| |
The
Fundamentals of Text-to-Speech Synthesis
(Continued
from Part 1)
From
Diphone-based Synthesis to Unit Selection Synthesis
For
the past decade, Concatenative Synthesis has been the
preferred method in industry for creating high-intelligibility
synthetic speech from text. Concatenative Synthesis
is characterized by storing, selecting, and smoothly
concatenating prerecorded segments of speech after possibly
modifying prosodic attributes like phone durations or
fundamental frequency. Until recently, the majority
of concatenative TTS systems have been diphone-based.
A diphone unit encompasses the portion of speech from
one quasi-stationary speech sound to the next: for example,
from approximately the middle of the /ih/ to approximately
the middle of the /n/ in the word "in". For
American English, a diphone-based concatenative synthesizer
has, at a minimum, about 1000 diphone units in its inventory.
Diphone units are usually obtained from recordings of
a specific speaker reading either "diphone-rich"
sentences or "nonsense" words. In both cases
the speaker is asked to articulate clearly and use a
rather monotone voice. Diphone-based concatenative synthesis
has the advantage of a moderate memory footprint, since
one diphone unit is used for all possible contexts.
However, since speech databases recorded for the purpose
of providing diphones for synthesis do not sound "lively"
and "natural" from the outset, the resulting
synthetic speech tends to sound monotonous and unnatural.
Any
kind of concatenative synthesizer relies on high-quality
recorded speech databases. An example fragment from
such a database is shown in Figure 3. The top panel
shows the time waveform of the recorded speech signal,
the middle panel shows the spectrogram ("voice
print"), and the bottom panel shows the annotations
that are needed to make the recorded speech useful for
concatenative synthesis.
In
the top panel of Figure 3, we see the waveform for the
words "pink silk dress". For the last word,
dress, we have bracketed the phone /s/ and the diphone
/eh-s/ that encompasses the latter half of the /eh/
and the first half of the /s/ of the word "dress".
For years, expert labelers were employed to examine
waveform and spectrogram, as well as their sophisticated
listening skills, to produce annotations ("labels")
such as those shown in the bottom panel of the figure.
Here we have word labels (time markings for the end
of words), tone labels (symbolic representations of
the "melody" of the utterance, here in the
ToBI standard [3]), syllable and stress labels, phone
labels (see above), and break indices (that distinguish
between breaks between words, sub-phrases, and sentences,
for example).
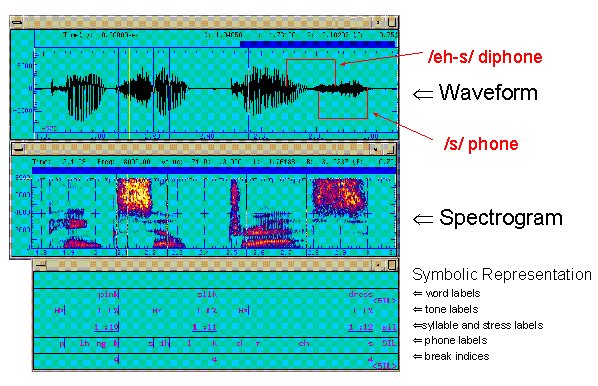
Figure
3: Short Segment of a Speech Database for Concatenative
TTS
It
turns out that expert labelers need about 100-250 seconds
of work time to label one second of speech with the
set depicted in Fig. 3 [4]. For a diphone-based synthesizer,
this might be a reasonable investment, given that a
"diphone-rich" database (a database that covers
all possible diphones in a minimum amount of sentences)
might be as short as 30 minutes. Clearly, manual labeling
would be impractical for much larger databases (dozens
of hours). For this, we would require fully automatic
labeling, using Speech Recognition tools. Fortunately,
these tools have become so good, that speech synthesized
from an automatically labeled speech database is of
higher quality than speech synthesized from the same
database that has been labeled manually [5].
Automatic
labeling tools fall into two categories: automatic phonetic
labeling tools to create the necessary phone labels
and automatic prosodic labeling tools to create the
necessary tone and stress labels, as well as break indices.
Automatic phonetic labeling is adequate, provided it
is done with a speech recognizer in "forced alignment
mode" (i.e., with the help of the known text message
so that the recognizer is only allowed to chose the
proper phone boundaries but not the phone identities).
The speech recognizer also needs be speaker-dependent
(i.e., be trained on the given voice), and has to be
properly bootstrapped from a small manually labeled
corpus. Automatic prosodic labeling tools work from
a set of linguistically motivated acoustic features
(e.g., normalized durations, maximum/average pitch ratios)
plus some binary features looked up in the lexicon (e.g.,
word-final vs. word-initial stress) [6], given the output
from the phonetic labeling.
With
the availability of good automatic speech labeling tools,
Unit-Selection Synthesis has become viable for obtaining
customer-quality TTS. Based on earlier work done at
ATR in Japan [7], this new method employs speech databases
recorded using a "natural" (lively) speaking
style. The database may be focused on narrow-domain
applications (such as "travel reservations"
or "telephone number synthesis"), or it may
be used for general applications like email or news
reading. In the latter case, unit-selection synthesis
can require on the order of ten hours of recording of
spoken general material to achieve customer quality,
and several dozen hours for "natural quality"
(see footnote 2). In contrast with
earlier concatenative synthesizers, unit-selection synthesis
automatically picks the optimal synthesis units (on
the fly) from an inventory that can contain thousands
of examples of a specific diphone, and concatenates
them to produce the synthetic speech. This process is
outlined in Figure 4, which shows how the method must
dynamically find the best path through the unit-selection
network corresponding to the sounds for the word 'two'.
The optimal choice of units depends on factors such
as spectral similarity at unit boundaries (components
of the "join cost" between two units) and
on matching prosodic targets set by the front-end (components
of the "target cost" of each unit). In addition,
there is the problem of having anywhere from just a
few examples in each unit category to several hundreds
of thousands of examples to chose from. Obviously, also,
the unit selection algorithm must run in a fraction
of real time on a standard processor.
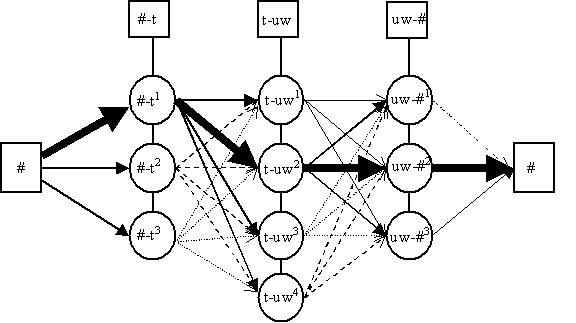
Figure
4: Illustration of Unit Selection for the Word "Two"
[Each node (circle) has a "target cost"
assigned to it while each arrow carries a "join
cost". The sum of all target and join costs is
minimal for the optimal path (illustrated with bold
arrows)]
In
respect to quality, there are two good explanations
why the method of unit-selection synthesis is capable
of producing customer quality or even natural quality
speech synthesis. First, on-line selection of speech
segments allows for longer fragments of speech (whole
words, potentially even whole sentences) to be used
in the synthesis if they are found with desired properties
in the inventory. This is the reason why unit-selection
appears to be well suited for limited-domain applications
such as synthesizing telephone numbers to be embedded
within a fixed carrier sentence. Even for open-domain
applications, such as email reading, however, advanced
unit selection can reduce the number of unit-to-unit
transitions per sentence synthesized and, consequently,
increase the segmental quality of the synthetic output.
Second, the use of multiple instantiations of a unit
in the inventory, taken from different linguistic and
prosodic contexts, reduces the need for prosody modifications
that degrade naturalness [8].
Another
important issue related to quality of the synthetic
speech is the choice of the voice talent one records.
A good voice can boost the quality rating of the synthesizer
by as much as 0.3 Mean Opinion Scores (MOS) above that
of an average voice (see
footnote 3).
Speeding
Up Unit Selection
As
outlined so far, Unit-Selection Synthesis will run too
slowly on any given computer. In practice, however,
we need to be able to run many channels of TTS on a
single processor. Note that in unit selection alone,
15% of the overall time is spent on candidate preselection
and target cost computation, 78% is spent on join costs
computation, and the rest (7%) is spent on the Viterbi
search and on bookkeeping, etc. Several options exist
to speed up unit selection. Clearly, one obvious way
to reduce the computational effort it to calculate target
costs only for the "top N" choices of a simpler/faster
preselection search (equivalent to limiting the beam
width of the main search). The effort for computing
the full target costs even for a smaller set of candidates,
however, may still be too large, because every potential
choice must be evaluated, given the sequence of phones
we want to synthesize in their context. One way to reduce
the computational requirements is to precompute the
target costs not for the exact set of units for a given
context (only known at runtime), but precompute the
target costs for a closely related ("representative")
set of n-phone (e.g., n=3) contexts. This set turns
out to be significantly smaller than the set of all
units of a particular unit type, and, as such, leads
to a speed-up by a factor of two, with no loss of synthesis
quality.
More
speed can be gained by attacking the join cost computation.
Note that for an NxN transition, N2 join costs need
to be computed. Since the join costs depend only on
the database, but not on the current utterance, we can
precompute them off-line. For this, we ran large amounts
of text through the TTS system and collected information
on which units get actually used. For example, we found
that with 10,000 full news articles synthesized (the
equivalent of 20 full days of reading), we encountered
about 50 million joins. We actually used 85% of all
units in the database, but only 1.2 million joins out
of 1.8 billion available, that is, only 0.07%. "Caching"
these join costs speeded up unit selection by a factor
of four. Coverage, that is, synthesizing other text
and evaluating how many of the chosen joins were in
the cache, revealed a "cache hit rate" of
about 99%. Note also that the fact that only a tiny
subset of all possible joins between units in the large
speech database gets used can be applied to reduce further
the representative set of contexts for target cost computation
(see above), resulting in a further reduction of the
amount of computation needed. With these methods we
succeeded in reducing the computational requirements
enough to be able to run several dozens of channels
on a standard PC processor.
Applications
One
of the most compelling application of TTS today is in
unified messaging. Figure 5 shows the Web interface
of an experimental unified messaging system at AT&T
Labs. Unified Messaging enables storing voice mail,
email, and fax within one unified mailbox that is accessible
via standard email clients, over the web, and, over
the phone. When accessed over the standard telephone,
email and fax messages need to be rendered in voice
by using a TTS.
Figure
5: Web Interface for an Experimental Unified Messaging
Platform at AT&T Labs
Another
application is (selective) reading of Web pages. Here,
like in email reading, special text "filters"
extract the information requested over the web and deliver
the related text to the TTS system that, in turn, renders
the message by voice. Services exist that call up customers
and alert them of stock prices having reached certain
thresholds, etc. Similarly, emergency weather alerts
are generated in form of text messages by the National
Weather Service and are being read via TTS over TV channels
and via the phone. Finally, with the increasing trend
to keep one's virtual office data "on the web",
access to critical elements such as calendar, appointment
and address books, as well as other "know-how"
may be provided to "road warriors" by TTS
over the phone.
In
the future, voice-enabled services such as the "How
May I Help You?" (HMIHY) system from AT&T Labs
[9] will revolutionize customer care and call routing.
In customer care, customers call in with questions about
a specific problem. In call routing, customers call
a central number, but need to be connected to another
location. TheHMIHY system, currently in limited deployment
in AT&T, fully automatically handles billing inquiries,
and 18 other frequent topics. Another variant of the
system reduces the cost of providing operator services.
HMIHY combines speech recognition, spoken language understanding,
dialogue management, and text-to-speech synthesis to
create an absolutely natural voice interface between
customers and voice-enabled service. The user may chose
any words, change his or her mind, hesitate, in short,
speak completely "naturally". In all cases,
the system reacts with a friendly voice.
Finally,
in a world that is getting more "broadband"
and more "multimedia" every day, TTS may provide
a compelling interface by not only synthesizing audio,
but also video. "Talking Heads" may serve
as focus points in (multimedia) customer care, in e-commerce,
and in "edutainment". As it did in audio-only
TTS, also in Visual TTS, Unit-Selection synthesis provides
the means to create compellingly natural-looking synthetic
renderings of talking people [10]. Who knows? Perhaps,
we will soon be watching Hollywood movies where the
actors have been synthesized in sound and image.
Conclusion
This
article summarized the changes in text-to-speech synthesis
over the past few years that now enable much more natural
sounding voice synthesis by computer. Unit-selection
synthesis provides improved naturalness "just in
time" to help push forward bleeding edge efforts
in voice-enabling traditional, as well as generating
completely new, telecom services.
While
fulfilling the vision of a seamless integration of real-time
communications and data over a single "Internet"
will largely depend on creating the infrastructure that
make system integration and connection of disjoint sub-systems
"easy" (such as through VXML), the quality
of critical infrastructure components such as the text-to-speech
(TTS) system is also important. After all, as said early
on in this paper, "TTS is closest to the customer's
ears!"
References
[1]
VoiceXML on-line tutorial at: http://www.voicexml.org/cgi-bin/vxml/tutorials/tutorial1.cgi
[2]
Sondhi, M. M., and Schroeter, J., Speech Production
Models and Their Digital Implementations, in: The Digital
Signal Processing Handbook, V. K. Madisetti, D. B. Williams
(Eds.), CRC Press, Boca Raton, Florida, pp. 44-1 to
44-21, 1997.
[3]
Silverman, K., Beckman, M., Pierrehumbert, J., Ostendorf,
M., Wightman, C., Price, P., and Hirschberg, J., ToBI:
A standard scheme for labeling prosody. ICSLP 1992,
pp. 867-879, Banff.
[4]
Syrdal, A. K., Hirschberg, J., McGory, J. and Beckman,
M., "Automatic ToBI prediction and alignment to
speed manual labeling of prosody," Speech Communication
(Special Issue: Speech annotation and corpus tools,
vol. 33 (1-2), Jan. 2001, pp. 135-151.
[5]
Makashay, M. J., Wightman, C. W., Syrdal, A. K. and
Conkie, A., "Perceptual evaluation of automatic
segmentation in text-to-speech synthesis," ISCLP
2000, vol. II, Beijing, China, 16-20 Oct. 2000, pp.
431-434.
[6]
Wightman, C. W., Syrdal, A. K., Stemmer, G., Conkie,
A. and Beutnagel, M., "Perceptually based automatic
prosody labeling and prosodically enriched unit selection
improve concatenative text-to-speech synthesis,"
ICSLP 2000, vol. II, Beijing, China, 16-20 Oct. 2000,
pp. 71-74.
[7]
Hunt, A., and Black, A., "Unit Selection in a Concatenative
Speech Synthesis System Using a Large Speech Database,"
IEEE-ICASSP-96, Atlanta,Vol. 1. pp. 373-376, 1996.
[8]
Beutnagel, M., Conkie, A., Schroeter, J., Stylianou,
Y. and Syrdal, A., "The AT&T Next-Gen TTS System,"
Proc. Joint Meeting of ASA, EAA, and DEGA, Berlin, Germany,
March 1999, available on-line at http://www.research.att.com/projects/tts/pubs.html.
[9]
A.L. Gorin, G. Riccardi and J.H. Wright, "How May
I Help You?", Speech Communication 23 (1997), pp.
113-127. Also see press release at http://www.att.com/press/item/0,1354,3565,00.html
[10]
Schroeter, J., Ostermann, J., Graf, H. P., Beutnagel,
M., Cosato, E., Syrdal, A., Conkie, A. and Stylianou,
Y., "Multimodal speech synthesis," ICME 2000,
New York, 2000, pp. MPS11.3.
Footnote
2:
A "natural-quality" TTS system would pass
the Turing test of speech synthesis in that a listener
would no longer be able, within the intended application
of the system, to say with certainty whether the speech
heard was recorded or synthesized. (return
to text)
Footnote
3:
Mean Opinion Score is a subjective rating scale where
"1" is "bad" and "5" is
excellent.
(return to text)

back
to the top

Copyright
© 2001 VoiceXML Forum. All rights reserved.
The VoiceXML Forum is a program of the
IEEE
Industry Standards and Technology Organization
(IEEE-ISTO).
|



