| |
The
Fundamentals of Text-to-Speech Synthesis
Introduction
Text-to-speech
(TTS) synthesis technology gives machines the ability
to convert arbitrary text into audible speech, with
the goal of being able to provide textual information
to people via voice messages. Key target TTS applications
in communications include: voice rendering of text-based
messages such as email or fax as part of a unified messaging
solution, as well as voice rendering of visual/text
information (e.g., web pages). In the more general case,
TTS systems provide voice output for all kinds of information
stored in databases (e.g., phone numbers, addresses,
car navigation information) and information services
(e.g., restaurant locations and menus, movie guides,
etc.). Ultimately, given an acceptable level of speech
quality, TTS could also be used for reading books (i.e.,
Talking Books) and for voice access to large information
stores such as encyclopedias, reference books, law volumes,
etc.
VoiceXML,
a Voice markup language, enables ubiquitous, interactive
speech services over the Web, and supports telephone
access to Web pages. . The following simple, yet illustrative,
example is taken from the online tutorial of VoiceXML
forum [1]. It simply plays a TTS prompt:
<?xml version="1.0"?>
<vxml application="tutorial.vxml" version="1.0">
<form id="someName">
<block>
<prompt>
Where do you want to go?
</prompt>
</block>
</form>
</vxml>
|
Here
the <prompt> tag causes the question to be rendered
by a TTS engine and then played over the phone.
Complementary
to (and a bit more realistic than) the above, a functional
block diagram for an application of highly advanced
speech technologies in a telecommunications setting
is depicted in Figure 1. The customer, shown at the
top center, makes a voice request to an automated customer-care
application. The speech signal related to this request
is analyzed by the Automatic Speech Recognition (ASR)
subsystem shown on the top right. The ASR system "decodes"
the words spoken and feeds these into the Spoken Language
Understanding (SLU) component shown at the bottom right.
The task of the SLU component is to extract the meaning
of the words. Here, the words "I dialed a wrong
number" imply that the customer wants a billing
credit. Next, the Dialog Manager depicted in the bottom
left determines the next action the customer-care system
should take ("determine the correct number")
and instructs the TTS component (shown in the top left)
to synthesize the question "What number did you
want to call?"
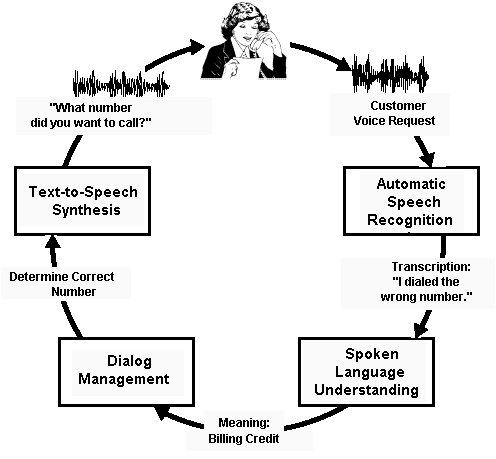
Figure
1: Flow Diagram of a Voice-Enabled Customer-Care Application
The
attentive reader will have noticed that, in the illustration,
the TTS output is "closest to the customer's ear".
Experience, indeed, shows that there is a tendency for
customers to weight TTS/speech output quality very heavily
in judging the quality of the overall voice-enabled
system. There is also the tendency to make this judgment
very quickly, after hearing just a few prompts. Therefore,
application developers and system integrators are rightfully
reluctant to adapt TTS technology, accepting only the
highest quality systems, or, at least for simple applications,
record static prompts using a human voice talent.
What
constitutes a high quality TTS system? TTS quality is
characterized by two factors; namely the intelligibility
of the speech that is produced, and the naturalness
of the overall message that is spoken. For the past
30 years or more, intelligibility has been the driving
factor in building TTS systems, since without high intelligibility,
TTS systems serve no useful purpose. As a result, most
modern TTS systems are highly intelligible, with formal
tests showing TTS word intelligibility approaching that
of naturally spoken speech. Until the mid-1990s, however,
significantly less success had been achieved in making
the synthetic speech sound natural, as if it came from
a recording of a human speaker. Experience has shown
that, even with high intelligibility, there exists a
minimum level of voice quality that is essential (we
call this 'customer quality') before consumers will
agree to both listen to synthetic speech on a regular
basis and pay for the services associated with using
the synthetic speech. Hence the objective of most modern
research in TTS systems is to continue achieving high
intelligibility, but, at the same time, to provide synthetic
speech that is customer quality or higher.
Clearly,
passing the Turing Test in synthesis for all possible
applications, for all kinds of input text, and with
all possible emotions expressed in the voice is not
possible today, but might be the topic of speech synthesis
research for several years to come. A more practical,
short-term approach is to start from the application
side and ask oneself what synthesis quality is "good
enough" for a given application and whether there
is technology today that might satisfy the requirements
of that specific application? For example, if all the
application needs to do is synthesize telephone numbers,
close-to-perfect results can be achieved quite easily
[try, e.g., http://www.research.att.com/~mjm/cgi-bin/saynum].
However, for a reasonably open domain such as news or
email reading, it would be dishonest to claim that synthesis
quality today is high enough to be judged completely
"natural-sounding."
This
article is organized as follows. First, we review established
methods for synthesizing speech from text. Then, we
focus on the method that has led to the highest quality
synthetic speech: concatenative TTS. Finally, we extend
concatenative TTS to include on-line Unit Selection
and explain how it achieves high naturalness while keeping
the computational requirements moderate.
"Traditional
Synthesis Methods
There
exist several different methods to synthesize speech.
Each method falls into one of the following categories:
articulatory synthesis, formant synthesis, and concatenative
synthesis.
Articulatory
synthesis uses computational biomechanical models of
speech production, such as models for the glottis (that
generates the periodic and aspiration excitation) and
the moving vocal tract. Ideally, an articulatory synthesizer
would be controlled by simulated muscle actions of the
articulators, such as the tongue, the lips, and the
glottis. It would solve time-dependent, 3-dimensional
differential equations to compute the synthetic speech
output. The interested reader is referred to [2] for
more information. Unfortunately, besides having notoriously
high computational requirements, articulatory synthesis
also, at present, does not result in natural-sounding
fluent speech (static vowels, for example, as well as
vowel-to-vowel transitions, can be synthesized sounding
"natural", but most stop consonants sound
mediocre at best). Speech scientists still lack significant
knowledge to achieve this somewhat elusive goal.
Formant
synthesis uses a set of rules for controlling a highly
simplified source-filter model that assumes that the
(glottal) source is completely independent from the
filter (the vocal tract). The filter is determined by
control parameters such as formant frequencies and bandwidths.
Each formant is associated with a particular resonance
(a "peak" in the filter characteristic) of
the vocal tract. The source generates either stylized
glottal or other pulses (for periodic sounds) or noise
(for aspiration or frication). Formant synthesis generates
highly intelligible, but not completely natural sounding
speech. However, it has the advantage of a low memory
footprint and only moderate computational requirements.
Concatenative
synthesis uses actual snippets of recorded speech that
were cut from recordings and stored in an inventory
("voice database"), either as "waveforms"
(uncoded), or encoded by a suitable speech coding method
(see footnote 1).
Elementary "units" (i.e., speech segments)
are, for example, phones (a vowel or a consonant), or
phone-to-phone transitions ("diphones") that
encompass the second half of one phone plus the first
half of the next phone (e.g., a vowel-to-consonant transition).
Some concatenative synthesizers use so-called demi-syllables
(i.e., half-syllables; syllable-to-syllable transitions),
in effect, applying the "diphone" method to
the time scale of syllables. Concatenative synthesis
itself then strings together (concatenates) units selected
from the voice database, and, after optional decoding,
outputs the resulting speech signal. Because concatenative
systems use snippets of recorded speech, they have the
highest potential for sounding "natural".
In order to understand why this goal was, until recently,
hard to achieve and what has changed in the last few
years, we need to take a closer look.
Concatenative
TTS Systems
A
block diagram of a typical concatenative TTS system
is shown in Figure 2. The first block is the message
text analysis module that takes ASCII message text and
converts it to a series of phonetic symbols and prosody
(fundamental frequency, duration, and amplitude) targets.
The text analysis module actually consists of a series
of modules with separate, but in many cases intertwined,
functions. Input text is first analyzed and non-alphabetic
symbols and abbreviations are expanded into full words.
For example, in the sentence "Dr. Smith lives at
4305 Elm Dr.", the first "Dr." is transcribed
as "Doctor", while the second one is transcribed
as "Drive". Next, "4305" is expanded
to "forty three oh five". Then, a syntactic
parser (recognizing the part of speech for each word
in the sentence) is used to label the text. One of the
functions of syntax is to disambiguate the sentence
constituent pieces in order to generate the correct
string of phones, with the help of a pronunciation dictionary.
Thus, for the above sentence, the verb "lives"
is disambiguated from the (potential) noun "lives"
(plural of "life"). If the dictionary look-up
fails, general letter-to-sound rules are used. Finally,
with punctuated text, syntactic and phonological information
available, a prosody module predicts sentence phrasing
and word accents and, from those, generates targets,
for example, for fundamental frequency, phoneme duration,
and amplitude. The second block in Fig. 2 assembles
the units according to the list of targets set by the
front-end. It is this block that is responsible for
the innovation towards much more natural sounding synthetic
speech. Then the selected units are fed into a back-end
speech synthesizer that generates the speech waveform
for presentation to the listener.
In
the last 3-4 years, TTS systems have become much more
natural sounding, mostly due to a wider acceptance of
corpus-driven unit-selection synthesis paradigms. In
a sense, the desire for more natural-sounding synthetic
voices that is driving this work was a natural extension
of the earlier desire to achieve high intelligibility.
We have started a new era in synthesis, where, under
certain conditions, listeners cannot say with certainty
whether the speech they are listening to was recorded
from a live talker, or is being synthesized. The new
paradigm for achieving very high quality synthesis using
large inventories of recorded speech units is called
"unit-selection synthesis".
What
is behind unit-selection synthesis and the corresponding
sea change in voice quality it achieves? Many dimensions
come to play. One important aspect is the ever-increasing
power and storage capacity of computers. This has direct
effect on the size of the voice inventory we can store
and work with. Where early concatenative synthesizers
used very few (mostly one) prototypical units for each
class of inventory elements, we can now easily afford
to store many such units. Other important aspects include
the fact that efficient search techniques are now available
that allow searching potentially millions of available
sound units in real time for the optimal sequence that
make up a target utterance. Finally, we now have automatic
labelers that speed up labeling a voice database phonetically
and prosodically. It is important to note that both,
the automatic labelers and the optimal search strategies
borrow heavily from speech recognition. In the following,
we will briefly touch upon these issues, after having
reviewed "diphone synthesis."
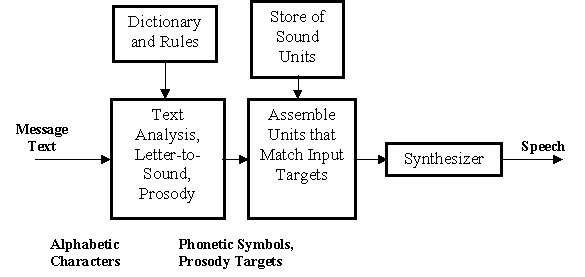
Figure
2: Block Diagram of TTS Synthesis System
Continued...
Footnote 1: Note
that, in order to achieve complete naturalness, any
speech codec (coder/decoder), used for TTS, needs to
be completely transparent, that is, speech that was
encoded and then decoded again needs to sound just like
the original. This means that the codec needs to work
at a relatively high bit rate.
(return to text)

back
to the top

Copyright
© 2001 VoiceXML Forum. All rights reserved.
The VoiceXML Forum is a program of the
IEEE
Industry Standards and Technology Organization
(IEEE-ISTO).
|



