| |
MRCP: a Standard Interface between VoiceXML Platforms and Speech Resources
Andrew Wahbe, Genesys
The Media Resource Control Protocol (MRCP) is an Internet Engineering Task Force (IETF) specification that describes a standard interface to media processing resources providing capabilities such as automatic speech recognition (ASR), speech synthesis (text-to-speech or TTS), as well as speaker identification and speaker verification (SI/SV). The key benefit of this technology is that it allows VoiceXML browsers to inter-operate with third party ASR, TTS, and SI/SV servers using an open, standardized protocol. Interoperability of this nature allows a given VoiceXML solution to be comprised of components from multiple vendors, benefiting technology providers by adding value to their products, while placing greater flexibility and choice in the hands of customers.
Key Benefits of MRCP
In the past, the purchase of a VoiceXML platform locked the buyer into a single, or at most a handful of ASR and TTS engines. Platform vendors required custom integrations with each supported speech engine; integrations which typically proved expensive. The interoperability provided by MRCP instead allows a customer to select a combination of VoiceXML platform and speech servers that best addresses their needs. Moreover, as needs change, customers have the freedom to swap one component for another. MRCP also allows a single VoiceXML deployment to use ASR and TTS resources from multiple vendors. For example, one vendor's engine could be used for one set of languages, and another vendor's engine could be used for other languages.
As MRCP is a network protocol rather than a software programming interface, speech resources can be deployed separately from the VoiceXML platform. A single MRCP server can host multiple resource types such as ASR, TTS and SI/SV. Alternatively, different types of resources may be hosted on distinct sets of servers. As a result, users have the freedom and flexibility to deploy and scale speech resources as needed.
By reducing integration cost and complexity, MRCP also serves as a strong value add to VoiceXML platform and speech resource vendors. For instance, engineering effort formerly allocated to custom integrations can be refocused on core technology and a single MRCP stack. Supporting a wider range of speech engines naturally increases the value of a VoiceXML platform. Conversely, speech engine vendors benefit from broader support in the market.
MRCP Standardization
The first version of MRCP (often referred to as MRCP v1) was developed by Cisco Systems, Inc., Nuance Communications, and Speechworks Inc., and is published by the IETF as Request For Comments (RFC) 4463. A revised version of the specification, MRCP v2, is currently under development by the IETF Speech Services Control (SpeechSC) working group. Speech servers and systems based on both MRCP v2 as well as the older MRCP v1 are available in the market today. As MRCP v2 reaches a stable RFC status within the IETF, however, systems based on MRCP v2 are expected to supplant those based on MRCP v1.
Because of the obvious importance of MRCP to the VoiceXML community, the VoiceXML Forum has established the MRCP Liaison Committee to maintain a relationship with the IETF’s SpeechSC working group. This committee is chartered with providing the IETF with feedback from the VoiceXML community—an effort that helps ensure that MRCP v2 meets the needs of VoiceXML-based systems. This committee also hopes to establish MRCP v2 conformance tests to help realize interoperability between VoiceXML platforms and MRCP v2 resources.
The MRCP v2 Protocol
MRCP v2 uses the Session Initiation Protocol (SIP) and the Session Description Protocol (SDP) for discovery and rendezvous -- essentially, establishing a session with a server that meets the client’s needs and negotiating how the two will communicate. SIP and SDP are commonly used in Voice over Internet Protocol (VoIP) communications to establish a call between two parties and negotiate how media will be exchanged. This media exchange usually takes place over separate channels using the Real-Time Protocol (RTP); SIP is only used to initially set up the call and to tear it down when either party hangs-up.
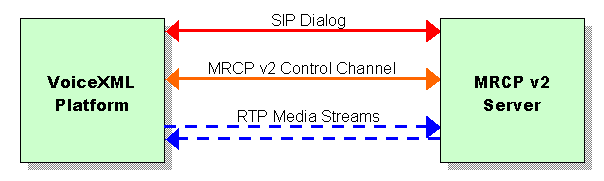
Figure 1: The basic architecture of an MRCP v2-based VoiceXML deployment
In addition to establishing the SIP dialog and media paths to speech resources, the SIP interaction that starts an MRCP session also creates a separate control channel used to exchange MRCP messages between the client and a speech server. Using this control channel, the client instructs the server to perform tasks such as speech recognition or speech synthesis on the media streams associated with a session. This basic architecture is depicted in Figure 1. Here, both the recognition and synthesis resources are on a single server. If these resources were instead deployed separately, then the architecture would appear as shown in Figure 2. Note that the telephony interface to the caller is not shown in either diagram. This interface is distinct from the one between the VoiceXML platform and the MRCP v2 server and may not necessarily be VoIP-based. For example, the caller may be connected to the VoiceXML platform using a circuit switched network system such as ISDN.
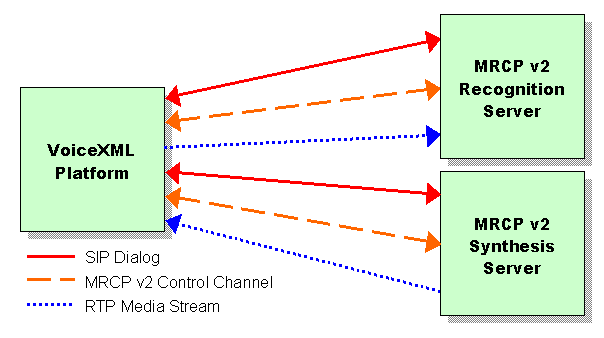
Figure 2: An MRCP v2-based VoiceXML deployment where synthesis and recognition resources are deployed separately
The MRCP v2 control protocol allows a client to receive progress updates as a request is being handled, and interrupt in-progress requests. Consider how these protocol features can be used to implement the VoiceXML “barge-in” feature, whereby prompt playback is stopped once the user has begun speaking. Using the scenario depicted in Figure 2 as an example, the speech recognition server sends an event to the client when the start of speech input is detected. The client then sends a separate MRCP request to the synthesis server, instructing it to abort TTS playback.
An important philosophy behind the design of MRCP v2 is the incorporation, wherever possible, of existing, established standards. This design philosophy has significant benefits for technology implementers, who can leverage existing technologies and knowledge, rather than reinventing solutions to previously solved problems. Consider, for instance, the choice to base MRCP v2 on SIP. SIP has been widely adopted as a control protocol for voice and other forms of communication such as video, and as such, an abundance of SIP resources and technologies are available. VoiceXML platform implementers may draw upon these SIP resources in the creation of an MRCP v2 stack. VoiceXML deployments based on MRCP v2 may also leverage SIP technologies, for example, to incorporate load balancing across speech resources.
MRCP v2 is also built upon many of the same World Wide Web Consortium (W3C) standards as VoiceXML, using the Speech Recognition Grammar Specification (SRGS) to specify speech recognition grammars and the Speech Synthesis Markup Language (SSML) to mark up text for speech synthesis. A format for representing the semantic results of speech recognition is currently missing from the standards; however, the W3C is working on the Extensible MultiModal Annotations language (EMMA) to meet this need. In the interim, MRCP v2 defines its own XML format for representing the semantic results of speech recognition but provides the flexibility for EMMA to be used in the future.
By building on existing IETF and W3C standards, MRCP v2 fits very naturally into VoiceXML-based architectures, even more so if those systems make use of SIP-based VoIP. As the protocol takes hold in the market, it promises to extend and enhance the benefits of the open standards it leverages. |