Enabling Speech & Multimodal Services on Mobile
Devices:
The ETSI Aurora DSR standards & 3GPP Speech Enabled Services
By
David Pearce
The desire for improved user interfaces for distributed
speech and multimodal services on mobile devices has
motivated the need for reliable recognition performance
over mobile channels. Performance needs to be robust
both to background noise and to any errors introduced
by the mobile transmission channel. There has been
much work in the telecommunications standards bodies
of ETSI and 3GPP to develop standards to achieve this
and enable interoperable services of high performance.
This paper provides an overview of the latest Distributed
Speech Recognition (DSR) standards that will be used
to support mobile speech services.
3GPP
(3rd Generation Partnership Project) is the body
that sets the standards for GSM and UMTS mobile communications.
In June 2004 3GPP approved the DSR Extended Advanced
Front-end as the recommended codec for “Speech
Enabled Services”. This selection was based on
extensive evaluations undertaken by two of the leading
ASR vendors (IBM & Scansoft) that confirmed the
performance advantages of DSR compared to the normal
voice codec. The significance of the selection by 3GPP
is that DSR will find widespread deployment in future
GSM and 3G mobile handsets that will usher in a new
wave of applications both for speech only services
and for distributed multimodal interfaces. This brings
with it implications not only for handset device manufactures
but also server vendors and application developers.
These developments are likely to be of interest to
the VoiceXML community as it extends the reach of applications
(existing and new) to the large numbers of mobile users
while delivering substantial improvements in performance
compared to the using the normal mobile voice channel.
By transporting the DSR speech features on the packet
data channel, speech can be easily combined with other
media, enabling new distributed multimodal services
on a single data channel. Thus DSR can be seen as an
enabler for the use of VoiceXML in multimodal services
using the capabilities of XHTML + VoiceXML (X+V).
1. Introduction to mobile
services & Distributed
Speech Recognition
It
is estimated that there are now 1.4 billion mobile
phone subscribers worldwide and the numbers continue
to grow. The market was originally fueled by person-to-person
voice communications and this remains the dominant “application”.
Recently we have seen increasingly sophisticated devices
packed with many new features including messaging,
cameras, browsers, games and music. Alongside device
developments the mobile networks have improved, giving
increased coverage and widespread availability of the
2.5G packet data such as GPRS. There is also the prospect
of many new deployments of 3G networks, bringing much
larger bandwidths to mobile users. The 2.5G and 3G
data capabilities provide the opportunity to deliver
a range of different audio and visual information to
the user’s device and enable access to “content” while
on the move. The user interface for these devices has
certainly improved but the small keypad remains a barrier
to data entry. Reliable speech input holds the potential
to help greatly. Alongside pure speech input and output,
the benefits of a multimodal interface are well appreciated.
The ability to combine alternative input modalities
(e.g. speech and/or keypad) with visual (e.g. graphics,
text, pictures) and/or audio output can greatly enhance
the user experience and effectiveness of the interaction.
For some applications its best to use a recognizer
on the device itself e.g. interfacing to the phone
functions and voice dialing using personal address
book. Although the computational power of these devices
is increasing, the complexity of medium and large vocabulary
speech recognition systems is beyond the memory and
computational resources of many devices. Also the associated
delay to download speech data files (e.g. grammars,
acoustic models, language models, vocabularies) may
be prohibitive or be confidential (e.g. a corporate
directory).
Server-side processing of the combined speech input
and speech output can overcome many of these constraints
by taking full advantage of memory and processing power
as well as specialized speech engines and data files.
New applications can also be more easily introduced,
refined, extended and upgraded at the server.
So, with the speech input remote from the recognition
engine in the server, we are faced with the challenge
of how to obtain reliable recognition performance over
the mobile network and hence be robust to the wireless
transmission channel. In addition we would like to
have an architecture that can provide a multimodal
user interface. These have been two motivators that
have led to the creation of the standards for Distributed
Speech Recognition (DSR):
- Improved
recognition performance over wireless channels.
The
use of DSR avoids the degradations introduced
by the speech codec & channel transmission
errors over mobile voice channels:
- By
using a packet data channel (for example GPRS for
GSM) to transport the DSR features
instead of the circuit switched voice channel that
is normally used for voice
calls, then the effects of
channel transmission errors are greatly reduced
and consistent performance is obtained
over the coverage area.
- By
performing the front-end processing in the device
directly on the speech waveform
rather than after transcoding with a voice codec, the degradations introduced
by
the codec are avoided.
- In
addition the DSR advanced front-end is very noise
robust and halves the error
rate in background noise compared to the mel-cepstrum front-end, giving robust
performance for mobile
users who
are often calling from environments where there is background noise.
- Ease
of integration of combined speech and data applications for multimodal interfaces.
In addition to applications using only speech input
and speech output, the benefits from multimodal interaction
are now well appreciated. In such multimodal interfaces,
different modes of input (including speech or keypad)
may be used and different media for output (e.g.
audio or visual on the device display) are used to convey
the information back to the user. The use of DSR
enables these to operate over a single wireless data transport
rather than having separate speech and data channels.
As such, DSR is a building block for distributed
multimodal interfaces.
2.
The ETSI DSR Advanced Front-end Standard ES 202
050
Between
1999 and 2002 ETSI Aurora conducted a competitive
selection process to create an Advanced DSR front-end
standard that would provide improved robustness compared
to the mel-cepstrum front-end. To support this, a new
performance evaluation process and associated speech
databases was created to allow the comparison between
candidates [8]. Three sets of noisy database were used
for these performance evaluations:
- Aurora-2
connected digits with simulated addition of noises
- Aurora-3
connected digits from real-world data collected
in vehicle (5 languages)
- Aurora-4
large vocabulary wall street journal dictation
with simulated noise
addition.
A scoring procedure was agreed that gave appropriate
weight to the results from each of the databases. The
winning candidate gave an average of 53% reduction
in word error rate compared to the DSR mel-cepstrum
standard (ES 202 108). Details of the Aurora-3 performance
results are given in section 2.1 below.
The front-end calculation is a frame-based scheme
that produces an output vector every 10 ms. In the
front-end feature extraction, noise reduction by two
stages of Wiener filtering is performed first. Waveform
processing is applied to the de-noised signal and mel-cepstral
features are calculated. Finally, blind equalization
is applied to the cepstral features.
The features produced from the Advanced Front-end
are the familiar 12 cepstral coefficients C0 and log
Energy, the same as for the Mel-cepstrum standard to
ensure easy integration with existing server recognition
technology.
The compression algorithm for the cepstral features
uses the same split vector quantisation scheme as the
earlier standard but with the quantiser tables retrained
for the Advanced Front-end.
2.1 Performance results on Aurora 3 database
In
this section results are presented for the five languages
making up the Aurora 3 database and using
the Hidden Markov Toolkit (HTK) recogniser in its “simple” configuration
ie 3 mixtures per state. The row(s) in each table labelled “0.4W+0.35M+0.25H” represent
the weighted average of the well matched, medium mismatch
and high mismatch results. Table 1 shows the absolute
performance for DSR using the Mel-Cepstrum Front-End,
which then serves as a baseline for the performance
comparisons with the Advanced Front-end.
| Aurora
3, Mel-Cepstrum Front-End |
| |
| Absolute
performance |
| Training
Mode |
Italian |
Finnish |
Spanish |
German |
Danish |
Average |
| Well
Matched |
92.39% |
92.00% |
92.51% |
91.00% |
86.24% |
90.83% |
| Medium
Mismatch |
74.11% |
78.59% |
83.60% |
79.50% |
64.45% |
76.05% |
| Medium
Mismatch |
50.16% |
35.62% |
52.30% |
72.85% |
35.01% |
49.19% |
| 0.4W+0.35M+0.25H |
75.43% |
73.21% |
79.34% |
82.44% |
65.81% |
75.25% |
| Table
1 |
The
top half of table 2 shows the absolute performance
that is obtained when the speech is processed by
the DSR Advanced Front End. The bottom half of
the table shows the relative performance when compared
to the DSR baseline that was given in 1.
| Aurora
3, Advanced Front-End |
| |
| Absolute
performance |
| Training
Mode |
Italian |
Finnish |
Spanish |
German |
Danish |
Average |
| Well
Matched |
96.90% |
95.99% |
96.66% |
95.15% |
93.65% |
95.67% |
| Medium
Mismatch |
93.41% |
80.10% |
93.73% |
89.60% |
81.10% |
87.59% |
| Medium
Mismatch |
88.64% |
84.77% |
90.50% |
91.30% |
78.35% |
86.71% |
| 0.4W+0.35M+0.25H |
93.61% |
87.62% |
94.09% |
92.25% |
85.43% |
90.60% |
| |
| Performance
relative to Mel-Cepstrum Front-End |
| Training
Mode |
Italian |
Finnish |
Spanish |
German |
Danish |
Average |
| Well
Matched |
59.26% |
49.87% |
55.41% |
46.11% |
53.85% |
52.90% |
| Medium
Mismatch |
74.55% |
7.05% |
61.77% |
49.27% |
46.84% |
47.89% |
| Medium
Mismatch |
77.21% |
76.34% |
80.08% |
67.96% |
66.69% |
73.66% |
| 0.4W+0.35M+0.25H |
69.10% |
41.50% |
63.80% |
52.68% |
54.60% |
56.34% |
| Table
2 |
As
shown in the tables above, the Advanced front-end
consistently gives half the error rate compared to
the mel-cepstrum. It provides state-of-the-art robustness
to background noise which was the major performance
criterion as part of the standard selection. In addition
to this the other aspect of robustness that is important
is robustness to channel transmission errors. DSR
has been demonstrated to be very robust in this dimension
too and it is possible to achieve negligible degradation
in performance when tested over realistic mobile
channel operating conditions. Reference [10] provides
a review of channel robustness issues.
2.2 VAD
Compared to the DSR mel-cepstrum standard, one further
enhancement coming from the Advanced Front-end is the
inclusion of a bit in the bitstream to allow the communication
of voice activity (VAD). The VAD algorithm marks each
10ms frame in an utterance as speech/non-speech so
that this information can optionally be used for frame
dropping at the server recogniser. During recognition,
frame dropping reduces insertion errors in any pauses
between the spoken words particularly in noisy utterances
and can be used for endpointing for training. It has
been found that performance is particularly helped
by model training with endpointed data. The VAD information
can also be used to reduce response time latencies
experienced by users in deployed applications by giving
early information on utterance completion.
3.
The ETSI DSR Extended Front-end Standards ES 202
211 & ES 202 212
ES 202 211 is an extension of the mel-cepstrum DSR
Front-end standard ES 201 108 [10]. The mel-cepstrum
front-end provides the features for speech recognition
but these are not available for human listening. The
purpose of the extension is to allow the reconstruction
of the speech waveform from these features so that
they can be replayed. The front-end feature extraction
part of the processing is exactly the same as for ES
201 108. To allow speech reconstruction additional
fundamental frequency (perceived as pitch) and voicing
class (e.g. non-speech, voiced, unvoiced and mixed)
information is needed. This is the extra information
that is provided by the extended front-end processing
algorithms at the device side that is compressed and
transmitted along with the front-end features to the
server. This extra information may also be useful for
improved speech recognition performance with tonal
languages such as Mandarin, Cantonese and Thai. The
compressed extension bits need an extra 800 bps on
top of the 4800 bps for the cepstral features.
In a similar way, ES 202 212 is the extension of the
DSR Advanced Front-end ES 202 050.
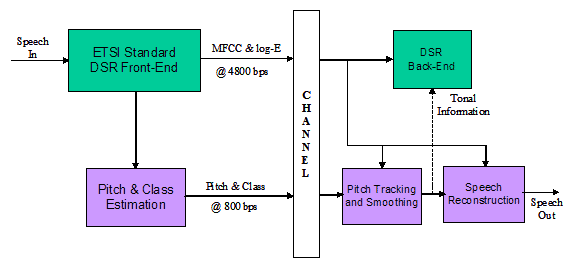
Figure 1: Extended DSR front-ends
One of the main use cases for the reconstruction is
to assist dialogue design and refinement. During pre-deployment
trials of services it is desirable to be able to listen
to dialogues and check the overall flow of the application
and refine the vocabulary used in the grammars. For
this and other applications of the reconstruction the
designer needs to be able to replay what was spoken
to the system at the server (off-line) and understand
what was spoken. To test this intelligibility of the
speech two evaluations were conducted. The first is
a formal listening test for intelligibility called
the Diagnostic Rhyme Test (DRT) that was conducted
by Dynastat listening laboratories. The results of
this are shown in table 3. For comparison the MELP
codec used for military communications was chosen as
a suitable reference. The DSR reconstruction performs
as well as MELP in the DRT tests giving confidence
that the intelligibility is good. The transcription
task is closer to what would occur in an actual application.
For this a professional transcription house was used
to transcribe sentences from the Wall Street Journal
that had been passed through the DSR reconstruction
and other reference codecs. Table 4 shows the results
with less than 1% transcription errors.
Type:
Coder: |
Noise |
| Clean |
Car
10dB |
Street
15dB |
Babble
15dB |
| Unprocessed |
95.7 |
95.5 |
92.4 |
93.8 |
| XFE
Reconstruction |
93.0 |
88.8 |
85.0 |
87.1 |
| XAFE
Reconstruction |
92.8 |
88.9 |
87.5 |
87.9 |
| LPC-10 |
86.9 |
81.3 |
81.2 |
81.2 |
| MELP |
91.6 |
86.8 |
85.0 |
85.3 |
| Table
3: Intelligibility listening tests using Diagnostic
Rhyme tests (conducted by Dynastat listening
laboratory) |
Type:
Coder: |
Noise |
| Clean |
Car |
Street |
Babble |
Clean |
Average
Error (%) |
| Unprocessed |
1,1,2 |
1,0,1 |
0,2,4 |
3,9,3 |
0,4,1 |
0.6 |
| XFE
Reconstruction |
1,6,1 |
0,3,6 |
2,9,4 |
5,9,2 |
1,4,5 |
1.0 |
| XAFE
Reconstruction |
0,6,2 |
0,5,4 |
0,4,3 |
3,5,2 |
1,6,5 |
0.8 |
| LPC-10 |
8,18,6 |
62,26,7 |
67,22,7 |
47,12,3 |
18,10,9 |
5.5 |
| MELP |
0,3,1 |
1,6,3 |
4,6,2 |
16,10,3 |
1,9,5 |
1.2 |
| No.
of words in message |
1166 |
1153 |
1155 |
1149 |
1204 |
Total:
5827 |
| Table
4:
Listening test transcription task results: Number
of missed/wrongly transcribed/partially transcribed
words |
The
pitch feature was also tested for tonal language
recognition of Mandarin and Cantonese and shown to
give better performance than proprietary pitch extraction
algorithms. Further information about the extension
algorithms and their performance can be found in
references [6, 7].
4. Transport Protocols the
IETF RTP Payload formats for DSR
In addition to the standards for the front-end features
themselves the protocols for the transport of these
features from the device to the server are also needed.
The IETF Real Time Protocols (RTP) are a well established
mechanism for the transport of many different media
types including video, VoIP, music etc. Associated
with RTP are also the SIP protocols for session initiation
and codec negotiation. By defining a RTP format for
the DSR features, services benefit from all the added
functionality of this set of protocols as well as the
support of other media types for multimodal applications.
The RTP payload formats for DSR have been agreed at
the IETF [11,12].
Within these payloads any number of frame pairs may
be sent within a packet. For the front-ends on their
own this takes 12 bytes per frame pair and with the
extension it is 14 bytes per frame pair. The choice
of the number of frame pairs to send in each payload
depends on the latency and bandwidth of the channel
available.
For a GSM GPRS channel then the raw uplink data capacity
available is 20bytes per 20ms slot (ie 8kbit/s). The
total overhead for the protocol headers in the stack
can be quite high as shown in the table below.
| Data |
Size
(bytes) |
| RTP |
12 |
| UDP |
8 |
| IP |
20 |
| LLC+SNDCP |
10 |
| Total |
50 |
In future networks it is expected that header compression
(RoHC) will be available reducing the 40 bytes for
the RTP, UDP, IP layers to about 4 Bytes. For current
GPRS networks the use of 4 or 8 frame pairs per payload
as a good compromise while for future networks with
RoHC it can be lower ie down to 1 frame pair per payload.
For speech output it is expected that speech encoded
for the network of the target device be used. E.g.
AMR for GSM devices. This output speech is also transported
over the GPRS packet data network using the RTP protocol.
It is common to have 4 slot downlink on GPRS networks
but even so it is recommended to use lower AMR data
rates such as 4.75kbit/s to keep up with the real-time
replay requirements.
5.
Speech Enabled Services in the 3rd Generation Partnership
Project (3GPP)
3GPP
is the body that sets the standards for GSM and UMTS
mobile communications. In 2002 3GPP conducted
a study and produced a technical report on the feasibility
of speech enabled services. The technical report [13]
provides an overview of the speech and multimodal services
envisaged and a new work item called Speech Enabled
Services (SES) was started. The SA4 codecs group within
3GPP has responsibility for the selection and recommendation
of the codec for SES. A selection procedure was agreed
in this working group consisting of “design constraints”, “test
and processing plan” and “recommendation
criteria” in the usual way. Two candidates for
the SES codec were considered: AMR and AMR-WB (being
the existing voice codec for 3GPP) and the DSR Extended
Advanced Front-end. Both of these being used over the
packet data channel rather than the circuit switched
channel that also suffers other degradations due to
the effects of transmission errors. To justify the
introduction of a new codec for SES services it was
seen as necessary to provide substantial performance
gain compared to the existing voice codec. Rather than
using HTK for the performance evaluations it was decided
that it would be best to use the talents of major server
recognition vendors for the evaluations. This would
enable a comparison between the performance that would
be obtained by a service either with DSR or using the
AMR voice codec. Two ASR vendors volunteered to undertake
the extensive testing, IBM and SpeechWorks (now Scansoft).
The performance evaluations were conducted over a wide
range of different databases some brought from 3GPP
but also proprietary databases owned by the ASR vendors.
Testing covered many different languages (German, Italian,
Spanish, Japanese, US English, Mandarin) environments
(handheld, vehicle) and tasks (digits, name dialling,
place names ….). In addition the codecs were
tested under block transmission errors. Results were
reported at SA4#30 meeting in Feburary 2004 in Malaga
and are summarised below. Note that results from both
the ASR vendors have been averaged in this table to
preserve anonymity the source.
5.1 Results from ASR vendor evaluations in 3GPP
| 8
kHz |
Number
of db tested |
AMR4.75
Average
Absolute Performance |
DSR
Average
Absolute Performance |
Average
Improvement |
| Digits |
11 |
13.2 |
7.7 |
39.9% |
| Sub-word |
5 |
9.1 |
6.5 |
30.0% |
| Tone
confusability |
1 |
3.6 |
3.1 |
14.8% |
| Channel
errors |
4 |
6.1 |
2.4 |
52.8% |
| Weighted
Average |
|
36% |
| Table
1: Low data-rate test |
| 8
kHz |
Number
of db tested |
AMR12.2
Average
Absolute Performance |
DSR
Average Absolute Performance |
Average
Improvement |
| Digits |
11 |
10.9 |
7.7 |
27.6% |
| Sub-word |
5 |
7.1 |
6.4 |
14.5% |
| Tone
confusability |
1 |
3.8 |
3.1 |
19.7% |
| Channel
errors |
4 |
5.5 |
2.4 |
40.9% |
| Weighted
Average |
|
25% |
| Table
2: High data-rate test at 8kHz |
| 16
kHz |
Number
of db tested |
AMR-WB12.65
Average Absolute Performance |
DSR
Average Absolute Performance |
Average
Improvement |
| Digits |
8 |
9 |
5.6 |
35% |
| Sub-word |
5 |
8.2 |
5.9 |
23.5% |
| Channel
errors |
4 |
6.1 |
3.4 |
42.2% |
| Weighted
Average |
|
31% |
| Table
3: High data-rate test at 16kHz |
The results show a substantial performance advantage
for DSR compared to AMR both at 8kHz and at 16kHz.
Based on the agreed recommendation criteria then DSR
was selected in SA4 for SES [14] and approved by 3GPP
SA in June 2004.
6.
Conclusions
The
performance advantages of DSR have been clear for
a while but to some extent the deployment of DSR
in the market has been constrained by the need to simultaneously
develop both ends of the system ie DSR in the mobile
devices and in the network recognition servers. It’s
been a bit of a “chicken and egg” conundrum
with server vendors waiting to see widespread availability
of DSR in handsets before making product commitments
and handset manufactures similarly asking “where
are the recognition servers to support applications?”.
The DSR Extended Advanced Front-end standards are now
in place together with its transport protocol. The
data connectivity provided by 2.5G GPRS networks to
support the transport of packet switched speech and
multimodal services are already widely deployed and
wider bandwidths of 3G data networks are being launched.
With the adoption of DSR by 3GPP we have an egg!
References
[1]
D Pearce, “Enabling New Speech Driven Services
for Mobile Devices: An overview of the ETSI standards
activities for Distributed Speech Recognition Front-ends” Applied
Voice Input/Output Society Conference (AVIOS2000),
San Jose, CA, May 2000
[2]
ETSI Standard ES 201 108 “Distributed Speech
Recognition; Front-end Feature Extraction Algorithm;
Compression Algorithm”, April 2000.
[3]
ETSI standard ES 202 050 “Distributed
Speech Recognition; Advanced Front-end Feature
Extraction
Algorithm; Compression Algorithm”,
Oct 2002
[4]
ETSI Standard ES 202 211 “Distributed
Speech Recognition; Extended Front-end
Feature Extraction
Algorithm; Compression Algorithm, Back-end
Speech Reconstruction Algorithm”,
Nov 2003
[5]
ETSI Standard ES 202 212 “Distributed
Speech Recognition; Extended Advanced
Front-end Feature Extraction
Algorithm; Compression Algorithm, Back-end
Speech Reconstruction Algorithm”,
Nov 2003
[6]
3GPP TS 26.243: “ANSI
C code for the Fixed-Point Distributed
Speech Recognition
Extended Advanced Front-end”
[7]
T Ramababran, A Sorin et al, “The
ETSI Extended Distributed Speech
Recognition (DSR) Standards: Client
Side Processing And Tonal Language
Recognition Evaluation”,
ICASSP 2004.
[8]
T Ramababran, A Sorin et al, “The ETSI Extended
Distributed Speech Recognition
(DSR) Standards: Server-Side Speech Reconstruction”,
ICASSP 2004
[9]
D Pearce, “Developing
The ETSI Aurora Advanced Distributed
Speech Recognition Front-End & What
Next?” ASRU 2001, Dec 2001
[10]
D Pearce, “Robustness
to Transmission Channel – the
DSR Approach”, Keynote
paper at COST278 & ICSA
Research Workshop on Robustness
Issues in Conversational Interaction,
Aug 2004.
[11]
Q Xie, RTP Payload Formats for ETSI European Standard
ES 202 050,
ES 202
211, and ES 202
212 Distributed
Speech Recognition Encoding,
http://www.ietf.org/internet-drafts/draft-ietf-avt-rtp-dsr-codecs-03.txt
[12]
Q Xie, "RTP Payload Format for ETSI European
Standard ES 201 108 Distributed
Speech Recognition Encoding", RFC 3557,
July 2003. http://www.ietf.org/rfc/rfc3557.txt
[13]
3GPP TR 22.977 “Feasibility study for
speech enabled services”,
Sept 2002
[14]
3GPP TR 26.943: ”Recognition performance
evaluations of codecs
for Speech Enabled Services(SES)”,
Nov 2004
|



