An
Introduction to Speech Recognition
(Continued
from Part 1)
How
it Works
Now
that we've discussed some of the basic terms and concepts
involved in speech recognition, let's put them together
and take a look at how the speech recognition process
works.
As you can probably imagine, the speech recognition
engine has a rather complex task to handle. The task
involves translating raw audio input into recognized
text that an application can process. As shown in Figure
1 below, the major components we want to discuss are:
- Audio
input
- Grammar(s)
- Acoustic
Model
- Recognized
text
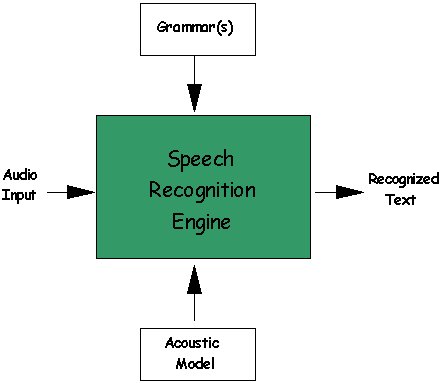
Figure 1: Components of a Speech
Recognition Engine
The
first thing we want to take a look at is the audio input
coming into the recognition engine. It is important
to understand that this audio stream is rarely pristine.
It contains not only the speech data (what was said)
but also background noise. This noise can interfere
with the recognition process, and the speech engine
must handle (and possibly even adapt to) the environment
within which the audio is spoken.
As
we've discussed, it is the job of the speech recognition
engine to convert spoken input into text. To do this,
it employs all sorts of data, statistics, and software
algorithms. Its first job is to process the incoming
audio signal and convert it into a format best suited
for further analysis. Once the speech data is in the
proper format, the engine searches for the best match.
It does this by taking into consideration the words
and phrases it knows about (the
active grammars), along with its knowledge of
the environment in which it is operating (for VoiceXML,
this is the telephony environment). The knowledge of
the environment is provided in the form of an acoustic
model. Once it identifies the most likely match
for what was said, it returns what it recognized as
a text string.
Most
speech engines try very hard to find a match, and are
usually very "forgiving." But it is important
to note that the engine is always returning it's best
guess for what was said.
Acceptance
and Rejection
When
the recognition engine processes an utterance, it returns
a result. The result can be one of two states: acceptance
or rejection. An accepted
utterance is one in which the engine returns recognized
text.
Whatever
the caller says, the speech recognition engine tries
very hard to match the utterance to a word or phrase
in the active grammar. Sometimes the match may be poor
because the caller said something that the application
was not expecting, or the caller spoke indistinctly.
In these cases, the speech engine returns the closest
match, which might be incorrect. Some engines also return
a confidence score along
with the text to indicate the likelihood that the returned
text is correct.
Not
all utterances that are processed by the speech engine
are accepted. Each processed utterance is flagged by
the engine as either accepted or rejected.
Speech
Recognition in the Telephony Industry
VoiceXML
uses speech recognition over the telephone, and this
introduces some unique challenges. First and foremost
is the bandwidth of the audio stream. The plain old
telephone system (POTS), as we know and love it, uses
an 8 kHz audio sampling rate. This is a much lower bandwidth
than, say, the desktop, which uses a 22kHz sampling
rate. The quality of the audio stream is considerably
degraded in the telephony environment, thus making the
recognition process more difficult.
The
telephony environment can also be quite noisy, and the
equipment is quite variable. Users may be calling from
their homes, their offices, the mall, the airport, their
cars--the possibilities are endless. They may also call
from cell phones, speaker phones, and regular phones.
Imagine the challenge that is presented to the speech
recognition engine when a user calls from the cell phone
in her car, driving down the highway with the windows
down and the radio blasting!
Another
consideration is whether or not to support barge-in.
Barge-in (also known as
cut-thru) refers to the
ability of a caller to interrupt a prompt as it is playing,
either by saying something or by pressing a key on the
phone keypad. This is often an important usability feature
for expert users looking for a "fast path"
or in applications where prompts are necessarily long.
When
the caller barges in with speech, it is essential that
the prompt be terminated immediately (or, at least,
perceived to be immediately by the caller). If there
is any noticeable delay (>300 milliseconds) from
when the user says something and when the prompt ends,
then, quite often, the caller does not think that the
system heard what was said, and will most likely repeat
what s/he said, and both the caller and the system get
into a confusing situation. This is known as the "Stuttering
Effect."
There
is also another phenomenon related to barge-in, and
that is called "Lombard Speech."
Lombard Speech refers to the tendency of people to speak
louder in noisy environments, in an attempt to be heard
over the noise. Callers barging in tend to speak louder
than they need to, which can be problematic in speech
recognition systems. Speaking louder doesn't help the
speech recognition process. On the contrary, it distorts
the voice and hinders the speech recognition process
instead.
Conclusions
Speech
recognition will revolutionize the way people conduct
business over the Web and will, ultimately, differentiate
world-class e-businesses. VoiceXML ties speech recognition
and telephony together and provides the technology with
which businesses can develop and deploy voice-enabled
Web solutions today! These solutions can greatly expand
the accessibility of Web-based self-service transactions
to customers who would otherwise not have access, and,
at the same time, leverage a business' existing Web
investments. Speech recognition and VoiceXML clearly
represent the next wave of the Web.

back
to the top

Copyright
© 2001 VoiceXML Forum. All rights reserved.
The VoiceXML Forum is a program of the
IEEE
Industry Standards and Technology Organization
(IEEE-ISTO).
|



