Testing
VoicexML Applications
Testing
VoiceXML applications includes four major components:
-
Testing the expected application flow or logic
- Testing
the recognition accuracy
- Performing
usability testing
-
Performance testing
This article will discuss the key considerations related
to VoiceXML application testing as well as strategies
and tactics used to speed testing in each of these areas.
Once tested applications are ready for commercial deployment,
many VoiceXML developers choose to outsource hosting
to a third party. This article will also discuss important
VoiceXML performance testing considerations for large-scale
commercial deployments of VoiceXML applications. By
examining various factors that affect performance and
discussing strategies to increase performance, developers
can be confident their applications will provide the
best possible experience to end-users.
Testing
Application Flow
Today
many VoiceXML developers perform application logic testing
and voice recognition testing simultaneously. These
two components are in fact independent and should be
treated as such. The most efficient way to test VoiceXML
applications is to decouple application flow testing
from voice recognition testing. VoiceXML applications
describe a dialog flow in which a user transitions from
one state to the next via prompts and responses. The
dialog flow can be represented visually using state
diagrams. For example, the following state diagram represents
an email reader written in VoiceXML:
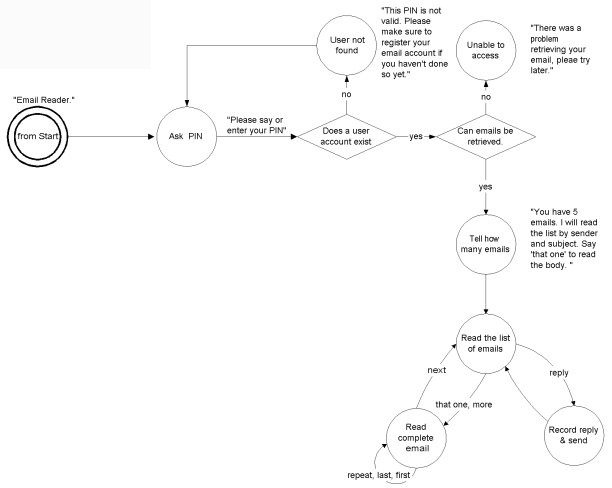
Figure
1: State Diagram for Email Reader
In
order to test the application flow, developers would
historically dial up their application and interact
with the application to test if the logic behaves consistent
with the design. This method can be quite tedious because
of the serial nature of an audio interface. Also, when
problems with recognition accuracy occur, testing application
flow becomes even more difficult and laborious. Today
there are many tools available for testing application
flow without using voice, audio, or a telephone. Interacting
with your VoiceXML application via text commands can
dramatically speed application flow testing. Once the
application flow behaves correctly in all given scenarios,
developers can transition to testing recognition accuracy.
Testing Recognition Accuracy
Testing
recognition accuracy, particularly for large grammars,
can also be tedious and time consuming. The process
for testing recognition accuracy generally involves
the following steps:
- Data
collection
- Transcription
of data
- Tuning
of grammars
Collecting
data involves correlating audio and recognition logs
of user interactions with your application. Generally
the larger the sample data size, the more thorough developers
can be in testing recognition accuracy. Diversity of
data is also important so that you can incorporate a
variety of voice samples for each different scenario.
Human
transcription is one of the most important aspects of
testing recognition accuracy because it is the only
way to objectively ascertain recognition performance.
Transcription of data can begin during the data collection
phase. Usually all three processes run for a period
of time in parallel so that developers can create a
positive feedback loop through the learnings of each
process. For example, if one particular recognition
sequence continues to cause problems, adjustments can
be made to accommodate the sequence and quickly test
the scenario in future tests.
Below
are the most common types testing recognition errors:
Out
of grammar utterances - Often
important in testing usability and dialog design, this
error occurs when users say things outside the grammar.
For example, if the user is navigating a browsable list
with commands like "previous, next, first one,
last one" and yet users say commands like "go
back" which is not in the grammar, an out of grammar
error will occur.
Substitution
errors - Occurs when words are confused because
they sound similar. For example, "Marquette street"
and "Market street" sound very similar and
could produce a substitution error if the grammar is
not properly tuned.
Insertion
errors - Occurs when the recognition result
returns extraneous words appended to the original utterance.
An example would be "Airport Way" as a returned
result of the utterance "airport."
Deletion
errors - Occurs
when the recognition result
returns an abbreviated version of the original utterance.
An example would be "two three" as a result
from the utterance "nine two three."
False
Accepts - The
utterance is not in the grammar and should have been
rejected.
False
Rejects - The
utterance is in the grammar and should have been recognized.
Based
on the types of errors above, there are several ways
to tune an application to improve recognition accuracy.
Below are the types of tuning developers can leverage
to increase recognition accuracy:
Phonetic
tuning - Words
in a given language can be modeled by translating the
sound of the words into a sequence of phonemes. In the
English language, there are 40 different phonemes. Here
are some examples of Computer Phonetic Alphabet representations:
bevocal
b I v o k * l
menu m E n j u
stock s t O k
quotes k w o t s
weather w E D *r
directions d *r E k S * n z
By
altering the phonetic dictionary, developers can increase
recognition rates for some sequences. Other examples
of phonetic tuning include adding alternate pronunciations
and adding crossword phonetic modeling. Here is an example
of adding crossword phonetic modeling:
palo_alto
p a l o a l t o
palo_alto p a l o w a l t o
palo_alto p a l a l t o
palo_alto p A l a l t o
palo_alto p a l w a l t o
palo_alto p A l w a l t o
Grammar
tuning - By
adding representative probabilities to confusion pairs,
developers can fix substitution errors. Also, adding
elements from the "out of grammar" list can
fix false accepts and correct rejects.
Recognition
tuning - There
are many runtime recognition parameters that can be
altered to yield better recognition rates. For example,
confidence rejection thresholds, pruning, and endpointing
behavior.
Tuning
the acoustic models and the endpointer -
Acoustic models use Hidden Markov Models of dozens of
speech features that represent all sounds occurring
in a given language. Endpointing describes when the
recognition engine should detect the beginning and ending
of speech.
Continued...

back
to the top

Copyright
© 2001 VoiceXML Forum. All rights reserved.
The VoiceXML Forum is a program of the
IEEE
Industry Standards and Technology Organization
(IEEE-ISTO).
|



